TL;DR: We introduce an LCM-based approach for propagating image-space losses to personalization model training and classifier guidance.
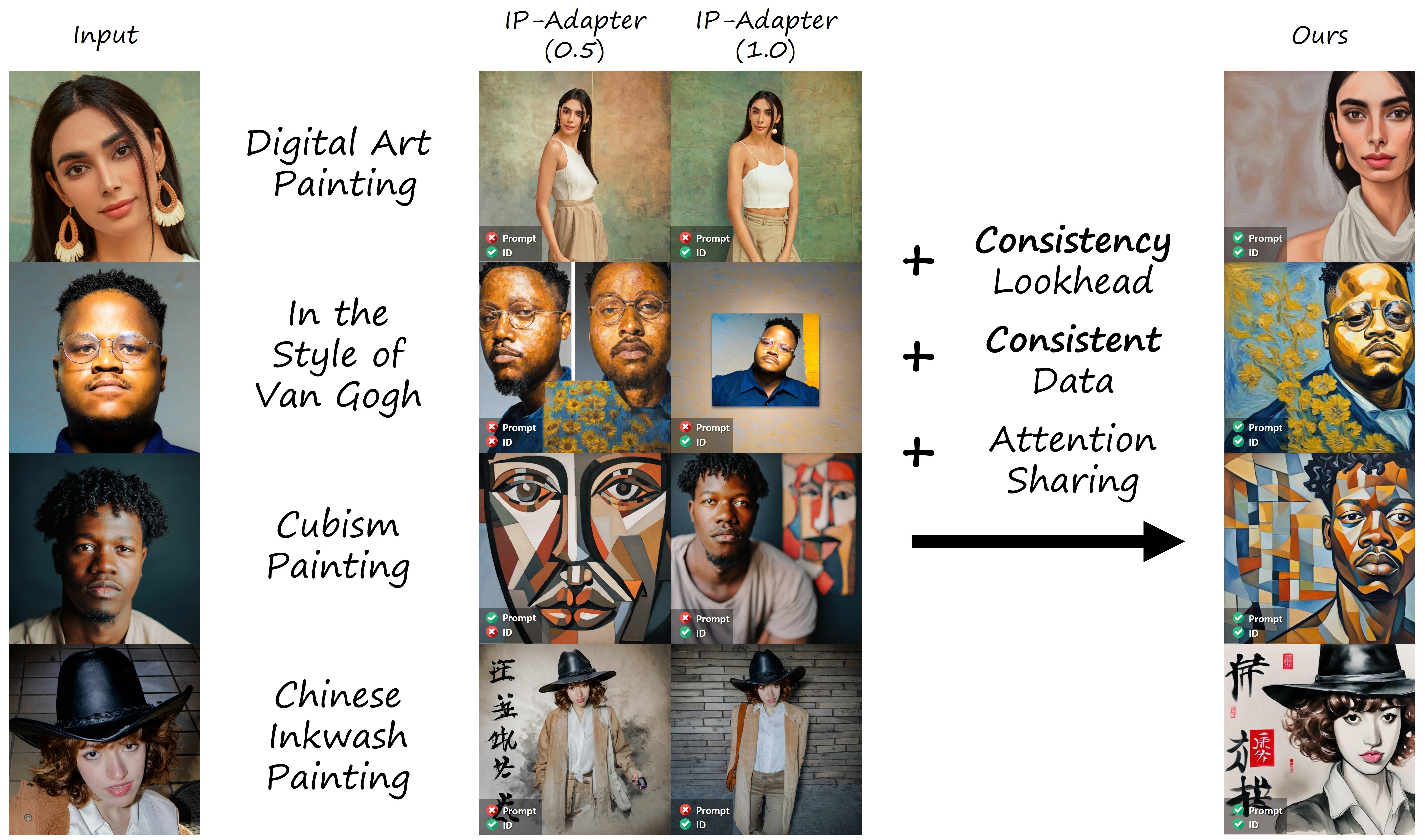
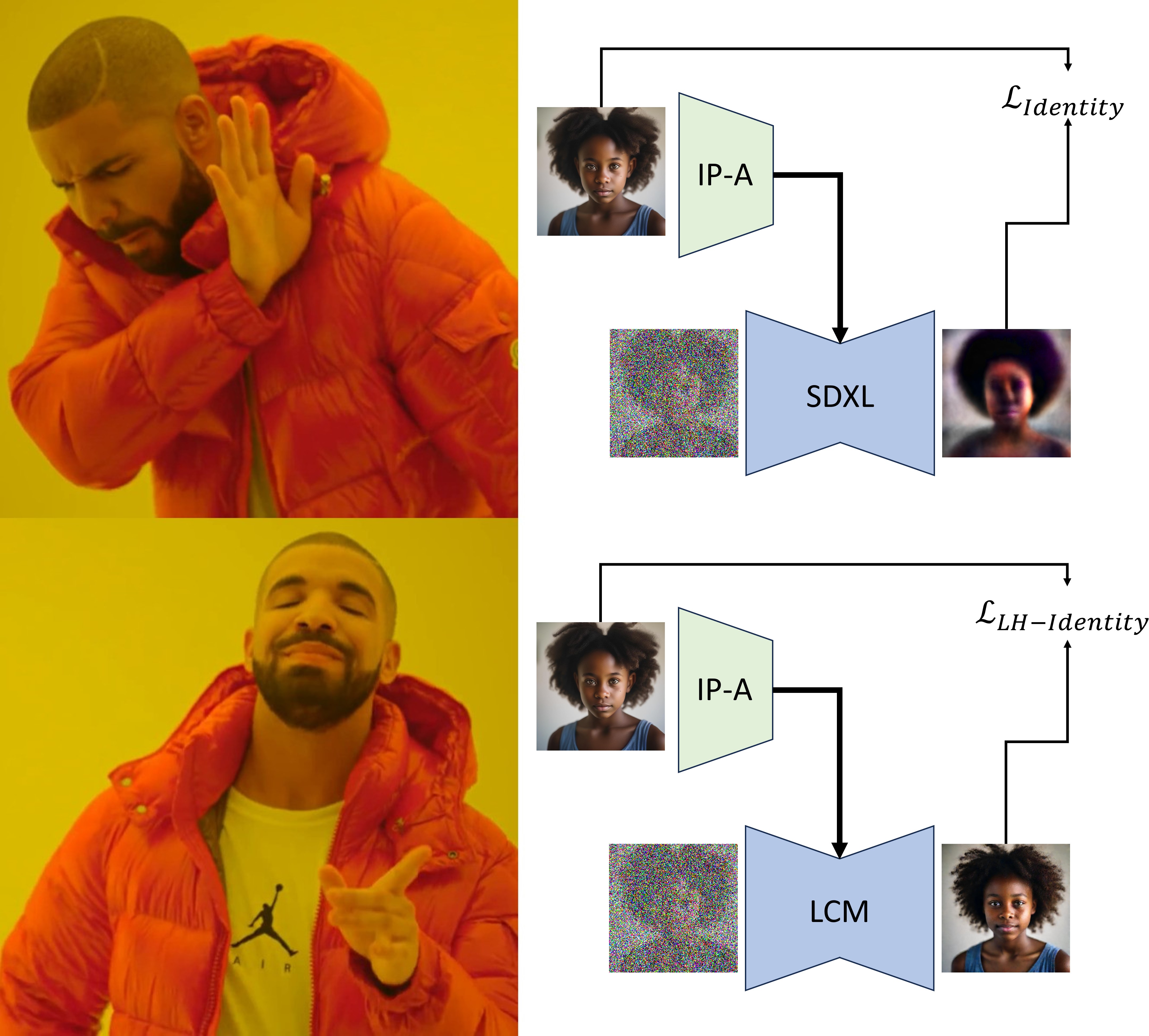
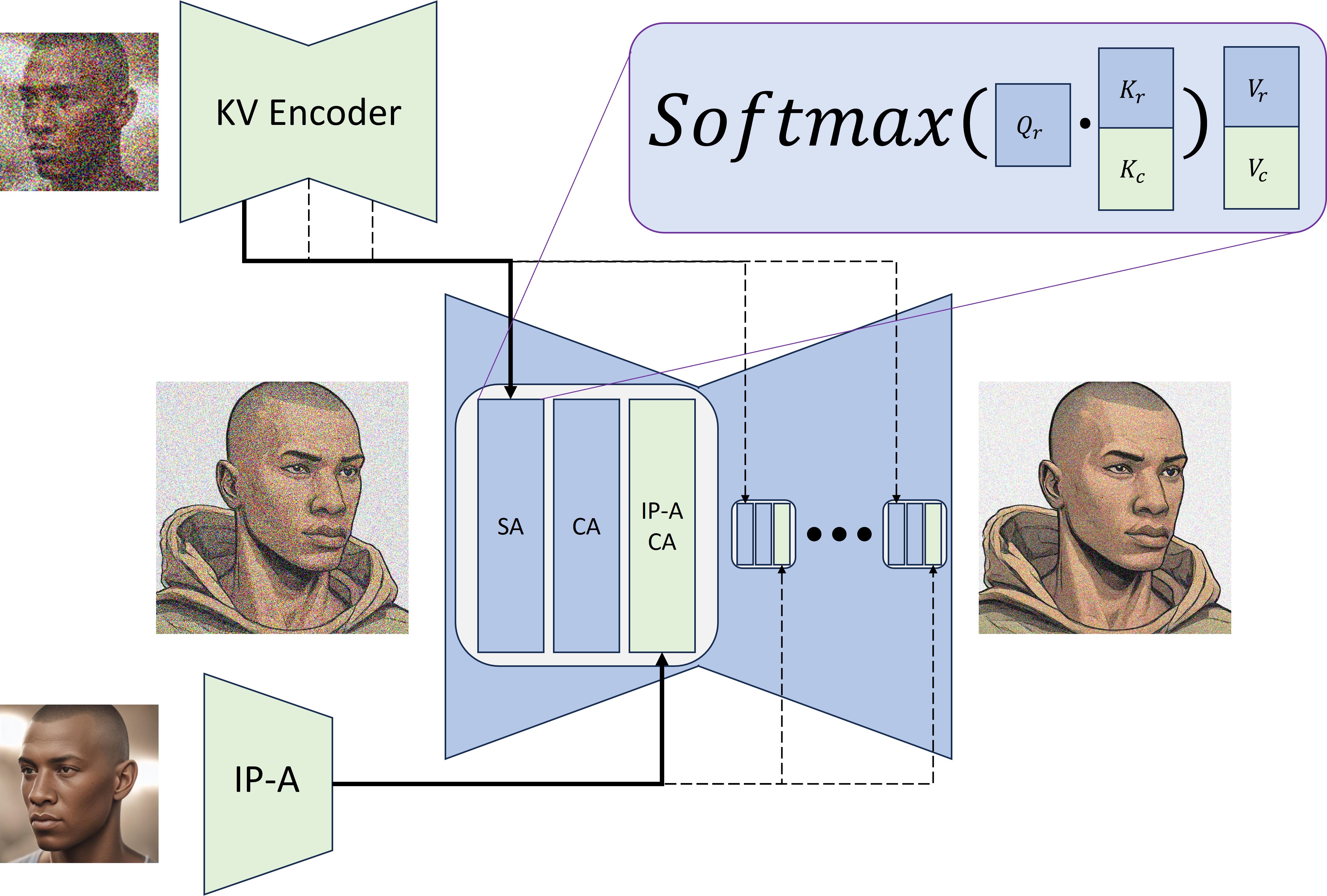
Recent advancements in diffusion models have introduced fast sampling methods that can effectively produce high-quality images in just one or a few denoising steps. Interestingly, when these are distilled from existing diffusion models, they often maintain alignment with the original model, retaining similar outputs for similar prompts and seeds. These properties present opportunities to leverage fast sampling methods as a shortcut-mechanism, using them to create a preview of denoised outputs through which we can backpropagate image-space losses. In this work, we explore the potential of using such shortcut-mechanisms to guide the personalization of text-to-image models to specific facial identities. We focus on encoder-based personalization approaches, and demonstrate that by tuning them with a lookahead identity loss, we can achieve higher identity fidelity, without sacrificing layout diversity or prompt alignment. We further explore the use of attention sharing mechanisms and consistent data generation for the task of personalization, and find that encoder training can benefit from both.







Our model attempts to preserve accesories that are unrelated to the identity and may be unwanted in follow-up generations. Since it trains on synthetic data where the target images may be stylized, it does not always default to photorealism when not prompted for an explicit style. Finally, it still struggle with rare concepts such as extreme makeup and unusual identities.
If you find our work useful, please cite our paper:
@misc{gal2024lcmlookahead,
title={LCM-Lookahead for Encoder-based Text-to-Image Personalization},
author={Rinon Gal and Or Lichter and Elad Richardson and Or Patashnik and Amit H. Bermano and Gal Chechik and Daniel Cohen-Or},
year={2024},
eprint={2404.03620},
archivePrefix={arXiv},
primaryClass={cs.CV}
}